Mobile device hardening using Puppet masterless

Managing a ton of devices is never a perfectly smooth road, but with a good level of automation, it will be closer to a walk in the park than a Baja race.
First of all, let's introduce the concept of hardening. What is usually called hardening, is simply the process of reducing the attack surface of systems to a minimum. Doing so implies ensuring that all the latest security patches are applied, that threats are remediated and that the systems' configuration is kept in check. Keeping all of this under control manually is quite a challenge and automating it will enable teams to gain back an enormous amount of time while reducing toil and human mistakes drastically.
Also, having an automated hardening solution is more and more required for infrastructure certification from third parties. And even when it is not required, it will make life much easier by having a way of ensuring that devices stay compliant with company requirements.
Of course, there are a few different tools to achieve this goal, most of which can be combined with others to offer full management of the devices. Among them the most popular are: Ansible, Chef and Puppet. This blogpost will be limited to Puppet for simplicity's sake.
Originally Puppet is meant to function in a server-client model with "masters" (server side) and "agents" (client side).
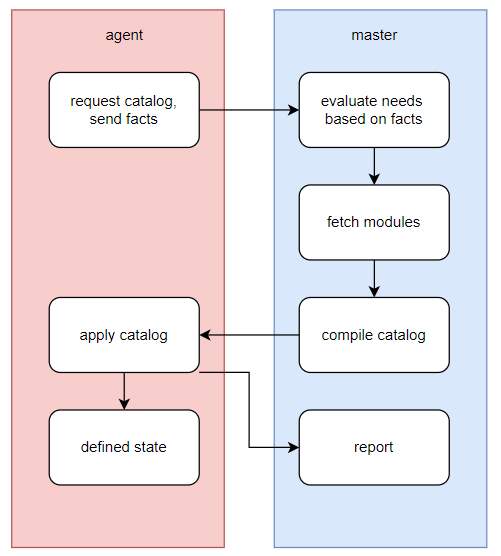
So how does the normal model work ?
- First, a master node will be setup so that agents can connect to it at regular intervals (which can be set in the agent configuration).
The master will keep an inventory of available modules (pieces of code that can be used together) and a hierarchy of key-value pairs that will be used to determine which value is to be used on each client. This key-value system is called Hiera and is definitely the major differentiating factor of Puppet today. - Once the agent contacts the master, the master will use data about the device called "Facts" (e.g. what OS is used, what hardware, what environment it is attached to, what function it serves) to determine which modules and module dependencies are needed for the device. The master will assemble all that code in what is called a "catalog" and then the master will verify if the catalog doesn't have major flaws (syntax errors, missing variables, deprecated functions) before sending it to the agent.
- Finally the agent will execute the catalog on the device and query the master for the Hiera values that it needs.
And without Masters ?
The masterless design on the other hand completely gets rid of the master.
Of course, this setup will have trade offs. The 2 biggest of them are the lack of "automatic packaging" since there is no master to compile a catalog for the agent and the lack of "secure" storage for your Hiera data. It is obviously not possible to store data in a master that does not exist, which means that all the values will have to be managed by the agent.
Then why go masterless? Simply for scaling purposes or because some environments don't have the possibility of giving permanent access to the masters from the devices.
The scaling part is quite self-explanatory: a few hundred (or thousand) agents will query tens of masters, every few hours, every day. That will lead to heavy network traffic and heavy load on the masters which could simply be avoided altogether if the agents were autonomous.
For the accessibility part let's take an example: in today's world, work-from-home has become a norm more than an exception. This means that employees and by extension their devices, may not be connected to a company network all the time when they are powered on. If an infrastructure is hosted on-premise and the masters cannot be exposed to the internet, having the possibility of keeping all the laptops hardened when outside of the company premises while not requiring permanent VPN connectivity can be critical.
How to go masterless ?
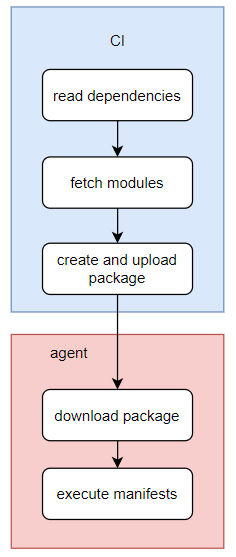
To get started with Puppet, the first thing to do is to write a module. A Puppet module is just a succession of steps that the agent will run (in a similar way to an Ansible playbook or a Chef cookbook). Once that module is written, it will need to be packaged with pdk (Puppet development kit). It will then be uploaded to a repository which is called a "Forge". This repository will be a feed for all the modules created by an organization from which they can be downloaded.
Every module can specify other modules as dependencies, which in turn can do the same. This is done in the metadata.json file inside the module itself. When Puppet is run with a master, the master can implicitly identify dependencies, which are then automatically added to the catalog.
When running in masterless mode, there will obviously be no master doing this for us so all the dependencies will need to be explicitly specified. Those dependencies will then need to be retrieved and packaged before getting sent to the agent.
The simplest way is to automate all of this in some form of CI pipeline (e.g. Jenkins, Azure Pipelines, Gitlab-CI, whatever floats your boat). The runner on which the pipeline is executed will first have to fetch all the dependencies specified in the metadata. json file from the forge. To do so we use a tool called librarian-puppet that is capable of querying the forge API and downloading all the modules locally. It is then simply a matter of creating the right folder structure for the agent before compressing all of this in some form of package or archive.
From there, the module simply needs to include a scheduled task that will trigger a puppet run whenever the conditions of the schedule are met.
Packaging
Now, it is only a matter of getting the package/archive to the client device and extracting it in the right place. This can be done in a lot of different ways including manual download and extraction of the archive, but having some kind of automatic deployment and update is nice. On Linux it is relatively trivial to just create a package repository, add another package source to your client and have the updates managed via yum, dnf or apt for example. It is possible to imitate the way this works on Linux on MacOS by using Homebrew or on Windows using Scoop or Chocolatey.
The neat part with the CI pipeline is that most offerings will allow to store encrypted key-value pairs to be used at runtime. This makes it possible to not hardcode Hiera values in the code, but have them pulled from the CI. This enables us to have different values based on certain parameters, for example which branch triggered the pipeline. This way the values will still be hardcoded in the final package deployed on the client, which might pose a problem for very sensitive data (like authentication tokens) so there is definitely room for improvement here.
With all of this, we made sure that all systems were following our security requirements and that configuration drift would be kept as low as possible. This in turn helps us provide a standard environment to our users with all the basics covered.